
Modern businesses rely heavily on server infrastructure to maintain application availability, protect sensitive data, and support daily operations. Yet many organizations underestimate the operational risk created by gaps in server support.
Even small inefficiencies: delayed responses, poor monitoring, weak escalation processes; can compound into extended downtime, compliance failures, and financial loss. Even a five-minute server outage can halt revenue, disrupt operations, and damage customer trust.
According to industry reliability studies, downtime can cost enterprises thousands of dollars per minute depending on workload criticality. Understanding where server support commonly fails is the first step toward reducing operational risk.
What Is Server Support Expected to Handle?
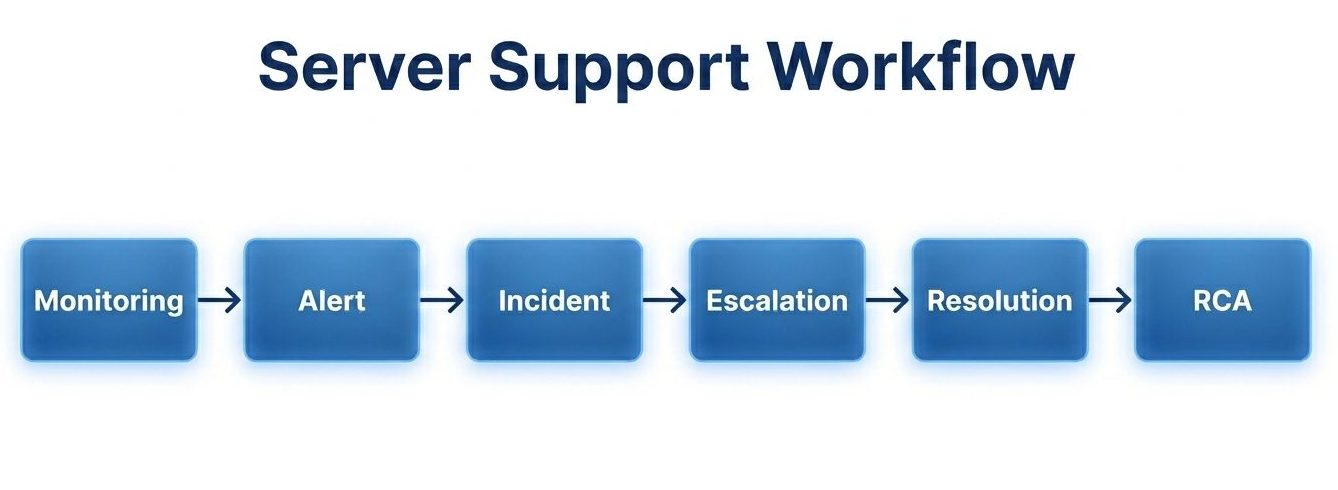
Effective server support goes beyond fixing outages. It includes continuous oversight, preventive maintenance, and structured incident management.
1. Incident Response
Server support teams must respond immediately when systems fail or degrade. Without rapid response:
- Minor issues escalate into major outages
- Recovery time increases
- Business operations are disrupted
Organizations operating under strict SLAs cannot afford delayed intervention.
2. Continuous Monitoring and Alerting
Monitoring tools detect anomalies before users are affected. Effective monitoring should:
- Track CPU, memory, and disk usage
- Monitor application performance
- Trigger real-time alerts
Without proactive monitoring, teams only react after customers experience problems.
3. Patch Management and Update Assistance
Regular patching reduces security vulnerabilities and performance issues. Server support teams:
- Evaluate patch impact
- Test updates
- Apply patches during change windows
Unpatched systems increase exposure to cyber threats and compliance violations.
4. Backup Oversight and Recovery Testing
Backup systems must be actively monitored and regularly tested. Support teams ensure:
- Backup jobs complete successfully
- Retention policies are maintained
- Recovery procedures are validated
Weak backup processes significantly increase the risk of permanent data loss.
5. Performance Troubleshooting and Root Cause Analysis
Recurring performance issues indicate deeper systemic problems. Effective support includes:
- Log analysis
- Resource bottleneck identification
- Root cause documentation
Without proper troubleshooting, incidents repeat and operational instability grows.
Common Server Support Gaps
Despite defined responsibilities, many organizations experience critical gaps.
Limited Availability
Support limited to business hours leaves systems vulnerable during nights and weekends. Many incidents occur outside standard working hours.
Without 24/7 coverage:
- Downtime increases
- Recovery is delayed
- Financial impact grows
Slow Response Times
Delayed acknowledgment or resolution extends system unavailability. Slow response:
- Increases mean time to recovery (MTTR)
- Impacts employee productivity
- Reduces customer trust
Lack of Proactive Monitoring
Reactive support models address issues only after failure. This results in:
- Frequent outages
- Emergency-driven operations
- Higher long-term costs
Weak Escalation Processes
Without structured escalation:
- Issues circulate between teams
- Resolution ownership becomes unclear
- Downtime expands
Complex infrastructure demands clear escalation paths.
Missing Documentation
Incomplete documentation slows down recovery efforts. Lack of:
- Server configuration records
- Network architecture diagrams
- Recovery procedures
can significantly delay troubleshooting during critical incidents.
| Support Gap | Operational Impact | Business Risk |
|---|---|---|
| Limited availability | Delayed response | Longer downtime |
| Slow response | Higher MTTR | Productivity loss |
| Weak monitoring | Undetected failures | Service outages |
| Poor escalation | Resolution delays | SLA violations |
| Missing documentation | Slow recovery | Extended incidents |
Skill Gaps in Hybrid Environments
Modern infrastructure often includes:
- On-premise servers
- Public cloud environments
- Hybrid architectures
Support teams lacking cross-platform expertise struggle to resolve issues efficiently.
For example, businesses running workloads on platforms like Amazon Web Services or Microsoft Azure require specialized cloud knowledge in addition to traditional server management skills.
How Server Support Gaps Increase Operational Risk
Extended Downtime
Poor escalation and slow response increase outage duration, leading to revenue loss and operational disruption.
Repeat Incidents
Failure to conduct root cause analysis results in recurring issues, signaling unresolved technical debt.
Data Integrity Risks
Weak backup validation increases the chance of:
- Data corruption
- Incomplete restores
- Permanent data loss
Compliance Failures
Industries governed by regulations require:
- Timely patching
- Secure configurations
- Documented change management
Gaps in server support may contribute to audit failures and financial penalties.
Customer Experience Impact
Frequent outages erode customer confidence. In competitive industries, service instability directly affects brand reputation and long-term retention.
Industry Trends Raising Expectations for Server Support
Today’s IT environments are:
- Always-on
- Cloud-integrated
- Security-sensitive
- SLA-driven
Hybrid workloads, stricter compliance standards, and rising cyber threats increase the importance of structured and proactive server support.
Organizations are shifting from reactive models to preventive, SLA-backed managed support frameworks. For example, a delayed patch in a payment processing server could expose customer transaction data and trigger compliance penalties.
What Effective Server Support Looks Like
24/7 Coverage
Round-the-clock support ensures rapid intervention and reduced downtime.
Clearly Defined SLAs
Service Level Agreements establish:
- Response times
- Resolution targets
- Accountability standards
Proactive Maintenance
Continuous monitoring and preventive updates help detect issues early, reducing downtime and avoiding emergency fixes. Regular patching, performance checks, and security scans keep systems stable and secure.
Structured Escalation Framework
A tiered support model ensures issues are handled by the right experts quickly. Clear escalation paths improve response times, minimize delays, and prevent repeated troubleshooting.
Documented Recovery Procedures
Well-maintained recovery guides enable fast, consistent incident resolution. Step-by-step documentation for backups, failover, and restoration reduces errors and ensures reliable service recovery.
Frequently Asked Questions
What is the biggest risk of weak server support?
Extended downtime and data loss are the most immediate risks. Over time, repeated failures also damage customer trust and regulatory standing.
How does proactive monitoring reduce operational risk?
Proactive monitoring detects anomalies before systems fail, reducing outage frequency and shortening recovery time.
Do small businesses need 24/7 server support?
If systems are customer-facing or revenue-critical, 24/7 support significantly reduces operational exposure, regardless of company size.
Conclusion
Server support gaps create measurable operational risk. Limited availability, slow response times, weak monitoring, and skill deficiencies can lead to downtime, compliance failures, and data integrity issues.
As IT environments grow more complex, structured and proactive server support becomes essential. Organizations that invest in continuous monitoring, clear SLAs, and documented recovery processes are better positioned to maintain uptime and protect business continuity.
Facing issues?
Our technical support
engineers can solve it.

